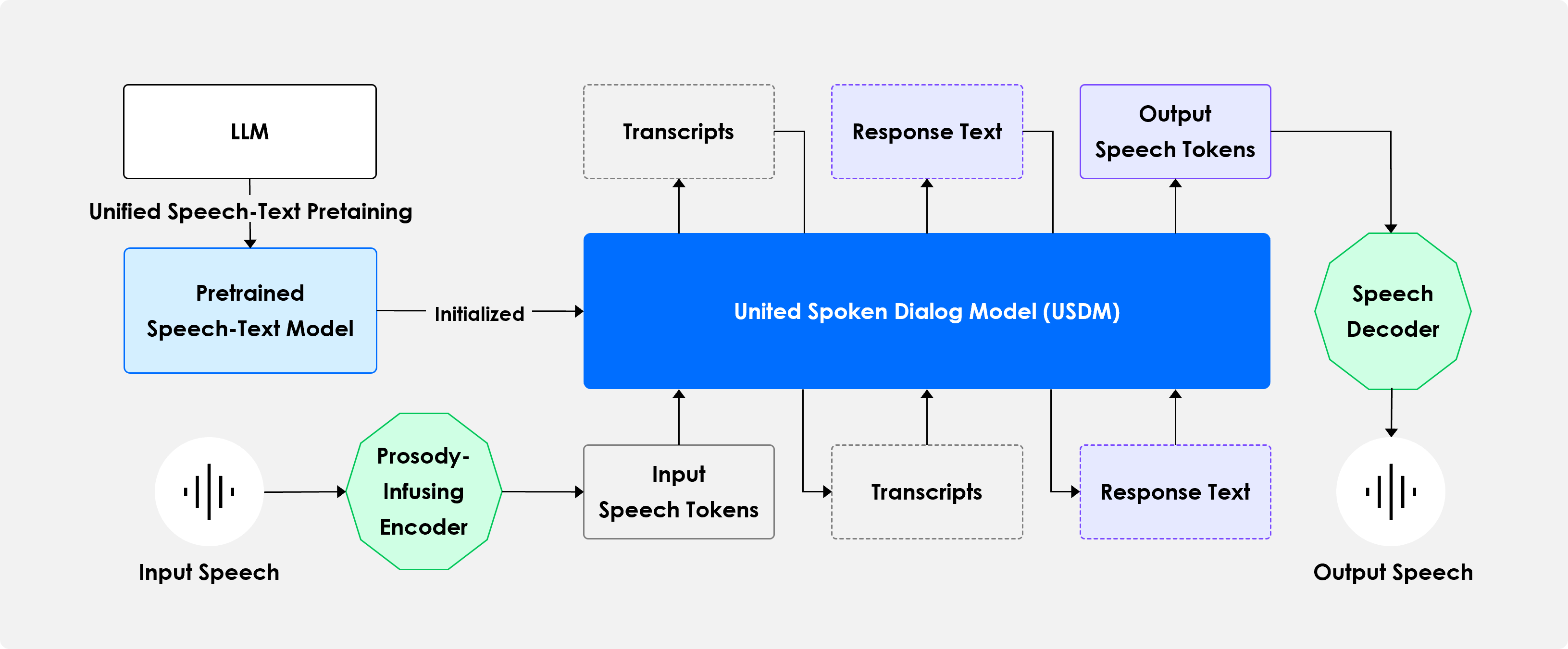
Overview of USDM
Sample 1
User Audio:

USDM Response:

Sample 2
User Audio:
USDM Response:
Sample 3
User Audio:
USDM Response:
Sample 1
Conversation History of Two UNSEEN Speakers:

USDM Response:
Sample 2
Conversation History of Two UNSEEN Speakers:
USDM Response:
Sample 3
Conversation History of Two UNSEEN Speakers:
USDM Response:
Sample 4
Conversation History of Two UNSEEN Speakers:
USDM Response:
Sample 1
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
Sample 2
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
Sample 3
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
Sample 1
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
Sample 2
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
Sample 3
User Audio:
Model Responses Comparison:
| Ground Truth | USDM | From Scratch | Cascaded | SpeechGPT |
|---|---|---|---|---|
We extracted XLS-R based unit from the original audio, and then only those units to reconstruct the audio 3 times. Through that sample, we can understand what information is contained in the units. We used speech from Expresso (Nguyen et al., 2023), Fisher (Cieri et al., 2004), and GigaSpeech (Chen et al., 2021) datasets.
Sample 1
| Ground Truth | Reconstructed Audio 1 | Reconstructed Audio 2 | Reconstructed Audio 3 |
|---|---|---|---|
Sample 2
| Ground Truth | Reconstructed Audio 1 | Reconstructed Audio 2 | Reconstructed Audio 3 |
|---|---|---|---|
Sample 3
| Ground Truth | Reconstructed Audio 1 | Reconstructed Audio 2 | Reconstructed Audio 3 |
|---|---|---|---|
@inproceedings{
kim2024paralinguisticsaware,
title={Paralinguistics-Aware Speech-Empowered Large Language Models for Natural Conversation},
author={Heeseung Kim and Soonshin Seo and Kyeongseok Jeong and Ohsung Kwon and Soyoon Kim and Jungwhan Kim and Jaehong Lee and Eunwoo Song and Myungwoo Oh and Jung-Woo Ha and Sungroh Yoon and Kang Min Yoo},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=NjewXJUDYq}
}